For years, the promise of AI in localization has been shadowed by a frustrating reality: unpredictability. Traditional monolithic prompts often ignore carefully curated glossaries, hallucinate technical tags, or lose a brand’s established voice.
At Crowdin, we are moving away from the take what you get approach of raw LLM outputs. Instead, we are introducing AI Pipelines – modular, multi-stage workflows that provide the guardrails and predictability needed for production-ready content.
Why modular logic beats single prompts
Relying on one massive prompt is a high-risk strategy. Even a linguistically correct translation can fail technically by breaking critical placeholders or ignoring formal registers.
The AI Pipeline app solves this by breaking the process into specialized, logical steps:
- Context Preparation: Analyzes project metadata to ensure the AI knows if “Open” refers to a file menu or an electrical circuit.
- Self-Correction Layer: Compares output against glossaries and technical constraints in real-time.
- Ambiguity Filtering: Identifies words with multiple meanings and flags them instead of forcing a 50/50 statistical guess.
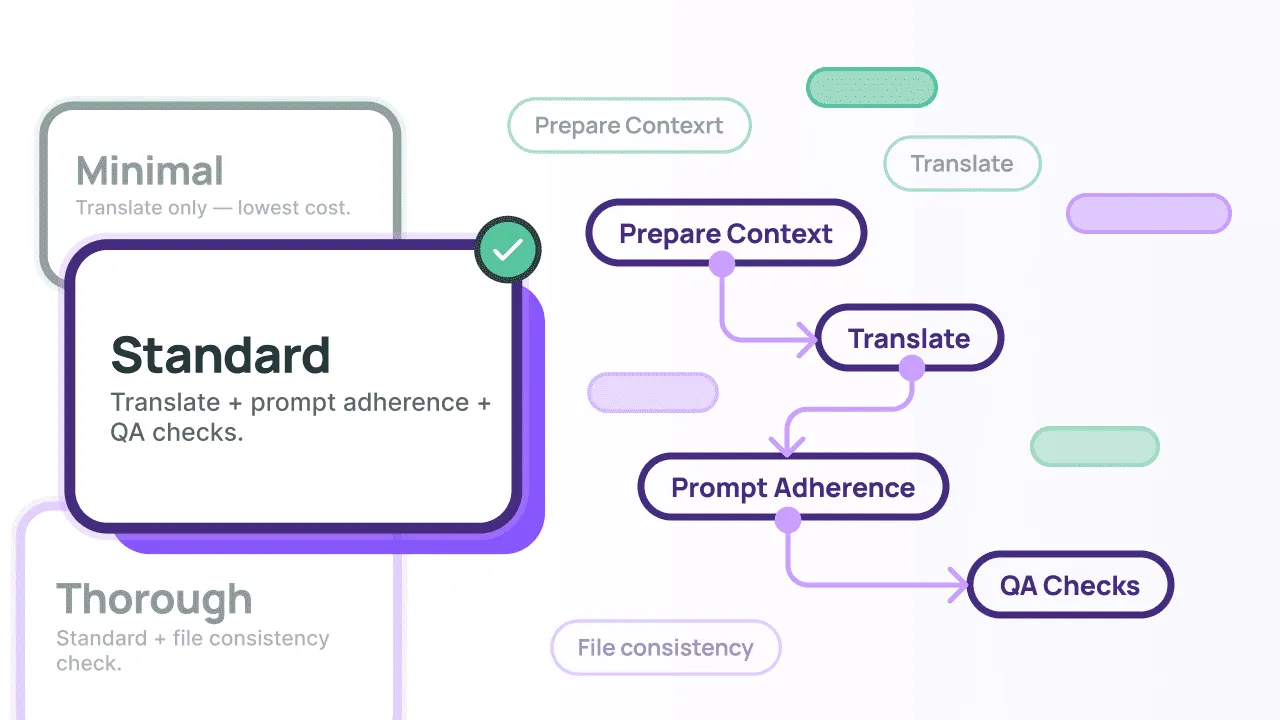
Choose your AI Pipeline preset
| Preset | Best For | Key Advantage |
|---|---|---|
| Minimal | Internal drafts, low-stakes content, or tight budgets. | Lowest cost; prevents fundamental errors through context. |
| Standard | Customer-facing apps, websites, and UI. | High prompt adherence via a dedicated Self-Correction Layer. |
| Thorough | Documentation, legal specs, or technical manuals. | Ensures 100% document-wide consistency. |
1. Minimal Preset
Even on a tight budget, direct AI translation is dangerous. The Minimal preset solves contextual blindness by introducing a Context Preparation phase. Before a single word is translated, the AI analyzes project metadata to understand, for example, whether the word “Follow” is a button to subscribe to a profile or a set of technical instructions to be carried out.
And only after this preparation step does the AI translation begin.

2. Standard Preset
For customer-facing UI, the real challenge is prompt adherence. Most AI errors happen because the model simply forgets the rules in the mid-translation phase.
After the context preparation and actual translation step, the Standard preset adds Prompt Adherence and QA Checks. These steps audit the translated output to ensure glossary terms are consistent, technical tags remain intact, and the brand’s established rules are perfectly maintained.
The best thing about this pipeline is that the AI corrects itself. There is no need to resolve the issues manually, so you see the already edited output ready for use.

3. Thorough Preset
The Thorough preset was designed specifically for long-form content where consistency is the top priority. It includes a File Consistency check that analyzes the entire document to ensure new updates perfectly match the terminology and style of the existing text.
However, this is a specialized tool that should only be used in specific cases:
- When to use it: It is a must for narrative or technical flow, such as documentation, help articles, or legal specs.
- When to skip it: There is no need to add this step for simple resource files (like a list of random app buttons) where strings aren’t related to each other.
By scanning the other 90% of a file, this preset ensures the new 10% doesn’t feel like a later update, maintaining a professional and unified voice throughout.

Custom AI Pipelines
While our presets cover the vast majority of needs, enterprise workflows aren’t always standard. Custom pipelines remain available for teams that need to build their own logic from scratch. You can use all the same modular steps found in the presets – adding, removing, or reordering them to fit your unique requirements.
The biggest advantage of going custom is the level of granular control you get over each stage:
- You can edit the AI prompts for every single step of your pipeline to match your exact internal requirements.
- Use the Place After setting to decide exactly where a new step belongs in the pipeline.
- Set specific rules to limit a pipeline step to run only for specific languages.
- You can apply steps only to files matching certain patterns, like
*.mdordocs//*.txt, ensuring the logic hits only the intended content.
Ambiguity Filter
The primary risk in translation happens when an AI model is forced to make a statistical guess. When an LLM hits a word with several possible meanings and no clear environmental clues, it won’t stop to ask for clarification. Instead, it gambles on a translation that might lead to an incorrect translation that ruins the experience for your users.
To solve this, you can add an Ambiguity Filter (or “Filter out” step) to any pipeline. This filtering process is performed before translation begins. Instead of letting the AI guess, this step identifies high-risk strings and flags them for review.
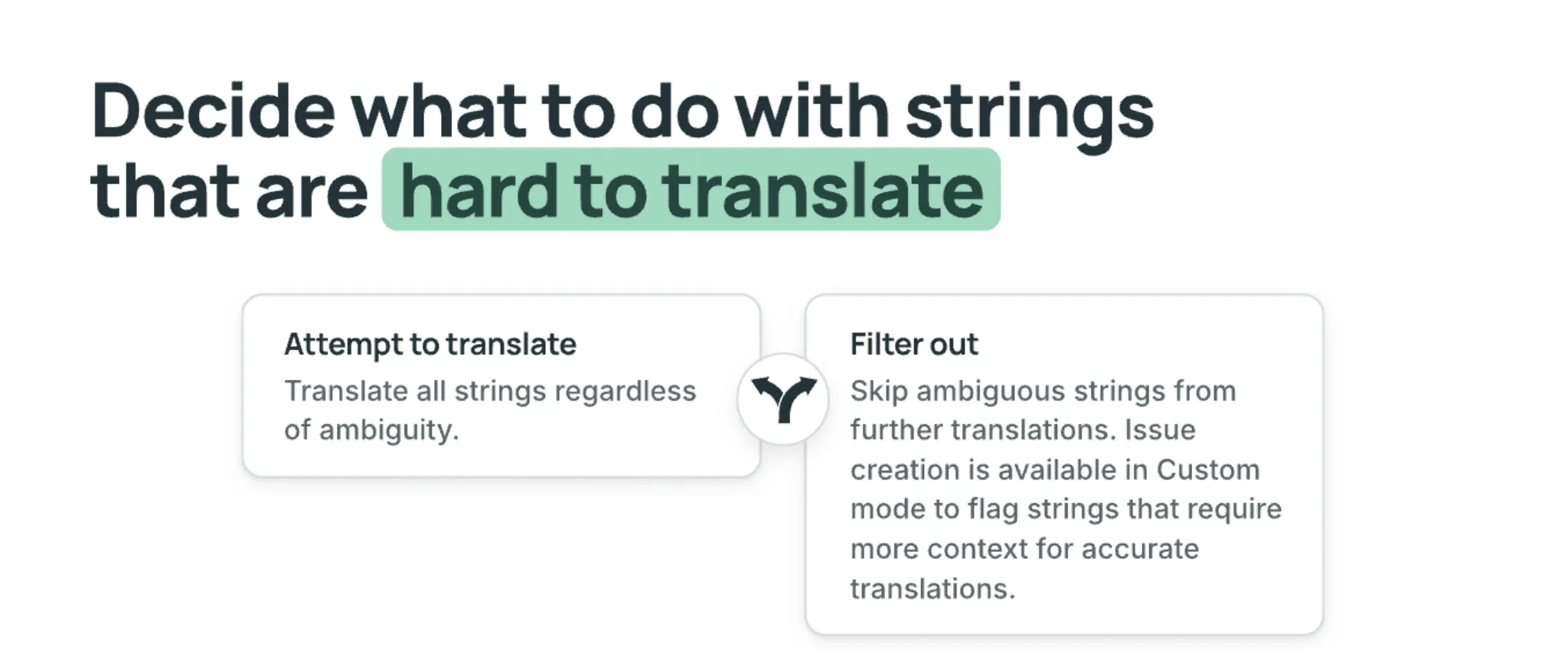
How the ambiguity filter works
This filter analyzes your strings based on strict logic to ensure only safe content moves forward:
- It uses project metadata, glossary terms, and even neighboring strings in the same file to resolve meaning.
- If a target language requires missing information (like speaker gender for Japanese or formal/informal choices for German and Spanish) the string is filtered out.
- The system follows a “when in doubt, filter out” rule. It is designed to prioritize human review over a “probably correct” AI guess.
Managing ambiguous strings at scale
Filtering doesn’t have to mean a mountain of manual labor if you use the AI Pipeline alongside Crowdin Copilot.
Instead of resolving strings one by one, Copilot groups similar ambiguities together. For example, if the word Balance is flagged in 50 different places, you provide the context once, and the fix is applied across the entire set.
By providing a small hint to the AI agent, it can handle complex grammatical errors across all related strings, saving time.
From AI translation to localization project management.
How it looks in practice
We tested this pipeline on a file with 42 strings. Instead of letting the AI guess and potentially make mistakes in translations, the Ambiguity Filter passed first.
AI translated 22 strings it was sure about and skipped the other 20 that were too vague. This is the big win: rather than a human proofreader having to check all 42 strings for hallucinations, they only had to look at the 20 specific ones the AI flagged. It basically creates a targeted to-do list for your team.
Check out the full workflow in the video here:
Real Example: Eliminating Language Contamination
The power of the AI Pipeline is best illustrated by Dr. Nadja Ruhl, LangOps Architect at Chainels. When translating Nordic languages with AI, a recurring challenge is “Swedish contamination” - where the AI accidentally slips Swedish words into Norwegian Bokmål.
To solve this, Dr. Ruhl utilized a custom AI Pipeline to edit the Translation step prompt directly. By adding a specific “Language-Specific Rules” section, she provided the AI with an explicit list of Norwegian equivalents for common Swedish “false friends” (like using være instead of vara). This granular control allows teams to document real errors found during QA and bake the fixes into the workflow, ensuring the AI maintains linguistic purity across related-language pairs.
Your choice: quality vs. rework time
It is important to be realistic: high-quality translation is rarely immediate. When adding specialized stages like Context Preparation, Prompt Adherence, and Ambiguity Filtering, the workflow naturally takes more time. This happens because the AI is actively thinking, which increases token consumption and extends processing times.
However, the real expense in modern localization isn’t the cost of tokens, but the time wasted fixing errors. Organizations now face a strategic trade-off:
- Fast AI, slow human review: Rapid results work for low-stakes content but often require extensive manual proofreading to repair broken tags, glossary mismatches, or gender context errors.
- Thorough AI, immediate use: A slightly slower pipeline delivers polished results that are ready for production the first time.
By investing a few extra minutes during the AI phase, you can reduce the manual cleanup needed afterward.
Ready to build your first AI Pipeline?
FAQ
What is an AI Localization Pipeline?
AI Pipeline is a Crowdin app that allows you to build multi-step translation workflows. Unlike a standard AI pre-translation, a pipeline breaks the process into modular steps – such as context analysis, terminology mapping, translation, and quality checks.
How do I prevent AI hallucinations in localization?
The key to preventing hallucinations is moving away from a single, long prompt. When you overwhelm an LLM with too many instructions at once (context, glossary, tone of voice, and formatting), it often “drifts” and starts inventing text.
AI Pipeline prevents hallucinations by using prompt sequencing and ambiguity filtering:
- Before translation even begins, the pipeline runs an ambiguity filter to identify high-risk strings. If a word has multiple meanings and lacks clear context, the AI is instructed to flag and filter it out rather than making a statistical guess.
- Instead of one big task, the app breaks the process into a chain of micro-tasks. One prompt collects context, another translates, while the next independent prompt is used to verify the output.
- A separate Prompt Adherence step is used to compare the translation against the prompt it was generated from. Were all the rules followed? If not, AI will correct itself.
- By isolating tasks, the AI stays grounded. It is much harder for the model to hallucinate when its only job in a specific step is to find and fix discrepancies.
Which AI Pipeline preset should I choose?
The choice depends on your project goals and the nature of your content:
- Minimal: Best for high-volume, low-visibility content or tight budgets. It focuses on speed and basic accuracy, adding a context-preparation step before starting the translation.
- Standard: The best choice for most UI and marketing projects. It adds automated QA and prompt adherence steps.
- Thoughtful: Choose this for documentation, help articles, or legal specs. It includes a File Consistency check, which analyzes the entire document to ensure new updates perfectly match the terminology and style of the existing text.
Does an AI Pipeline take longer than a single-prompt pre-translation?
Yes, it does – but for a good reason. While a single-prompt AI translation is nearly instantaneous, it often misses nuances or breaks formatting. An AI Pipeline takes more time because it performs multiple passes over the text.
However, the total time to market is actually shorter:
- The output is much closer to human-grade translation.
- Because the AI performs its own QA and editing, your human linguists spend less time fixing errors.
- You spend slightly more on AI tokens upfront to save a massive amount on manual post-editing (MTPE) costs later.
Yuliia Makarenko
Yuliia Makarenko is a marketing specialist with over a decade of experience, and she’s all about creating content that readers will love. She’s a pro at using her skills in SEO, research, and data analysis to write useful content. When she’s not diving into content creation, you can find her reading a good thriller, practicing some yoga, or simply enjoying playtime with her little one.